利用讯飞星火API打造智能办公助手
引言
最近一直在做一些事情,感觉很繁琐我就想能不能交给AI来处理,但是如果要一条一条问的话也很繁琐...我就想我之前把讯飞星火接入了微信,实现自动回复,于是把讯飞星火接入到python的想法应运而生,我要狠狠地压榨讯飞星火
一、讯飞星火API简介
讯飞星火API是科大讯飞推出的智能大模型接口,具备较强的的自然语言处理能力(前提是你没有用过GPT),适用于文本生成、信息提取、语义分析等场景。我们可以通过简单的接口调用,将AI能力集成到我们需要的工作中。
讯飞星火API优势:
高效自然语言处理:支持文本摘要、对话生成、问答等功能。便捷集成接口:开发者只需简单配置,即可快速接入API。灵活的行业应用:适合教育、办公、金融等多种行业。免费!
二、讯飞星火API申请步骤
打开讯飞星火官网。
登录账号(没有账号的需要先注册)。
创建一个应用
登录之后点击控制台
点击创建新应用
内容随便填都可以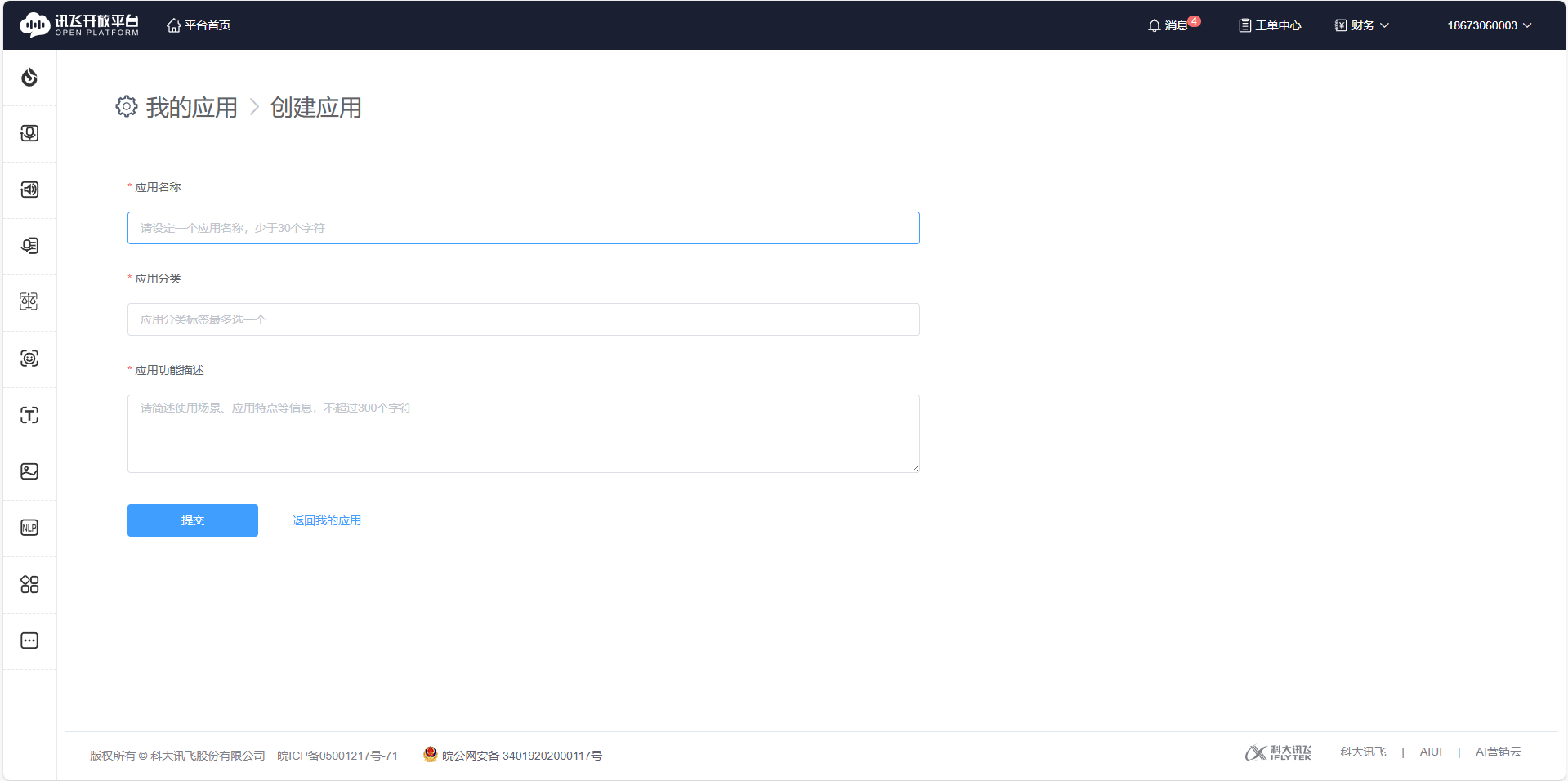
4.白嫖免费的token礼包。得认证才行!!!!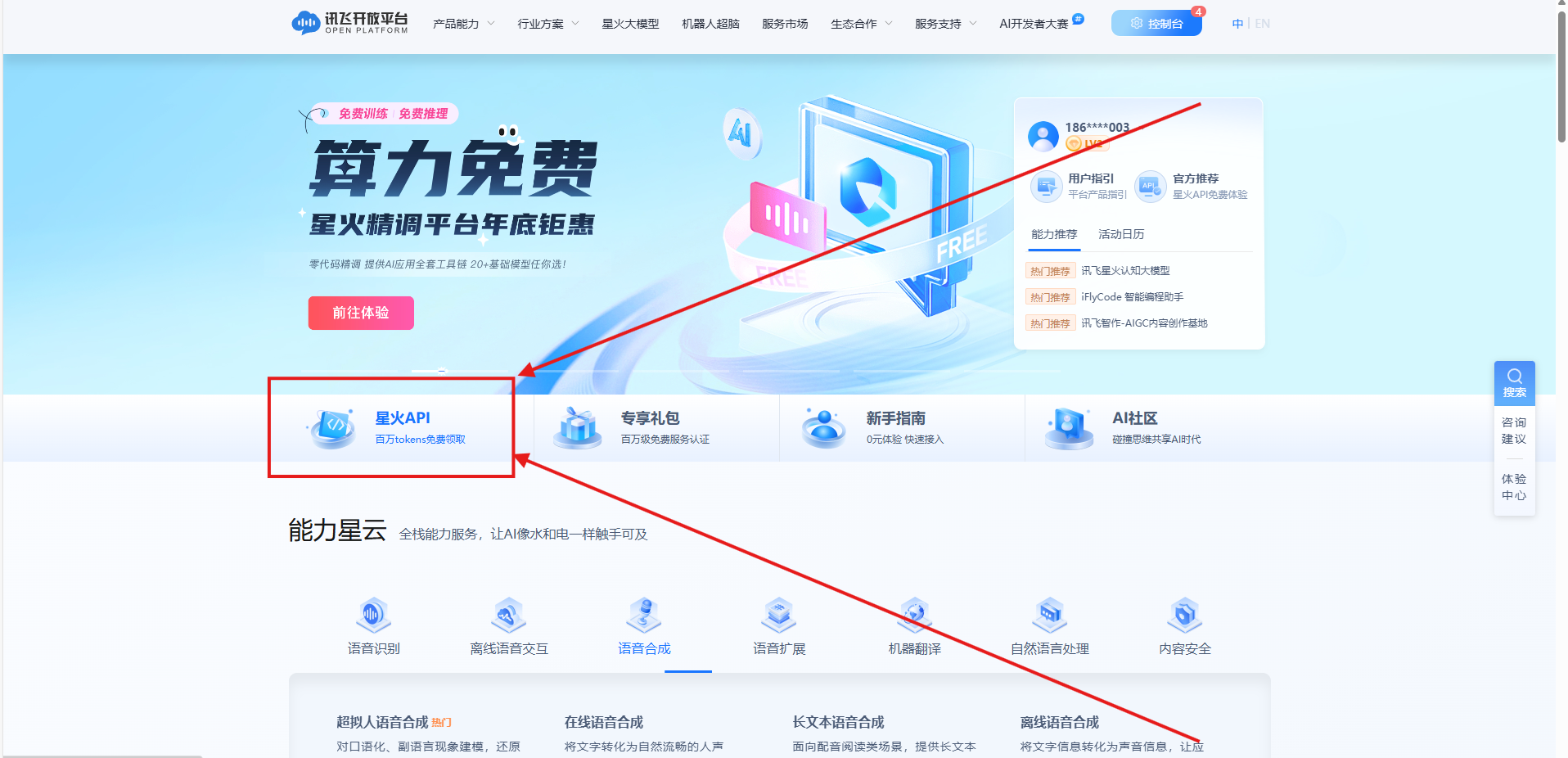
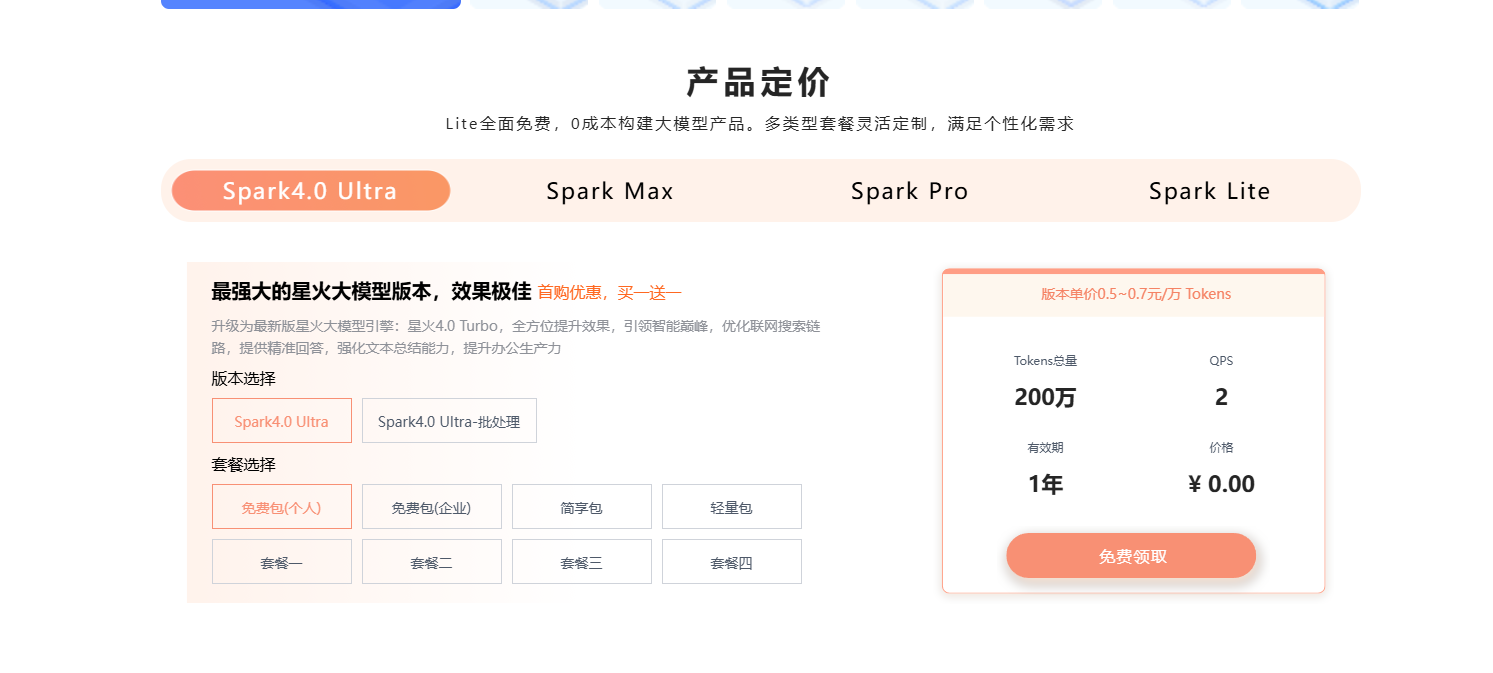
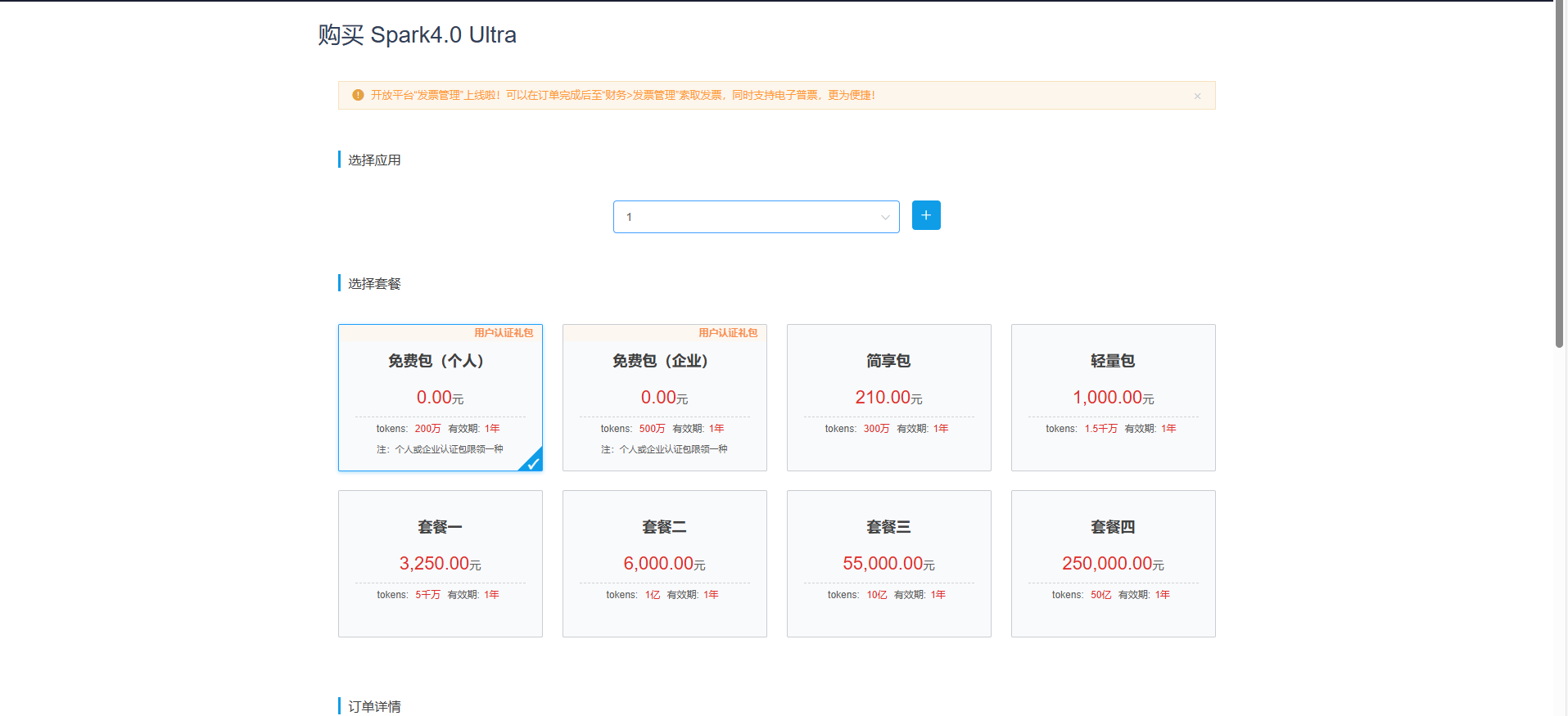
5.查看信息
购买之后接着点击开始调试之后会进入到控制台 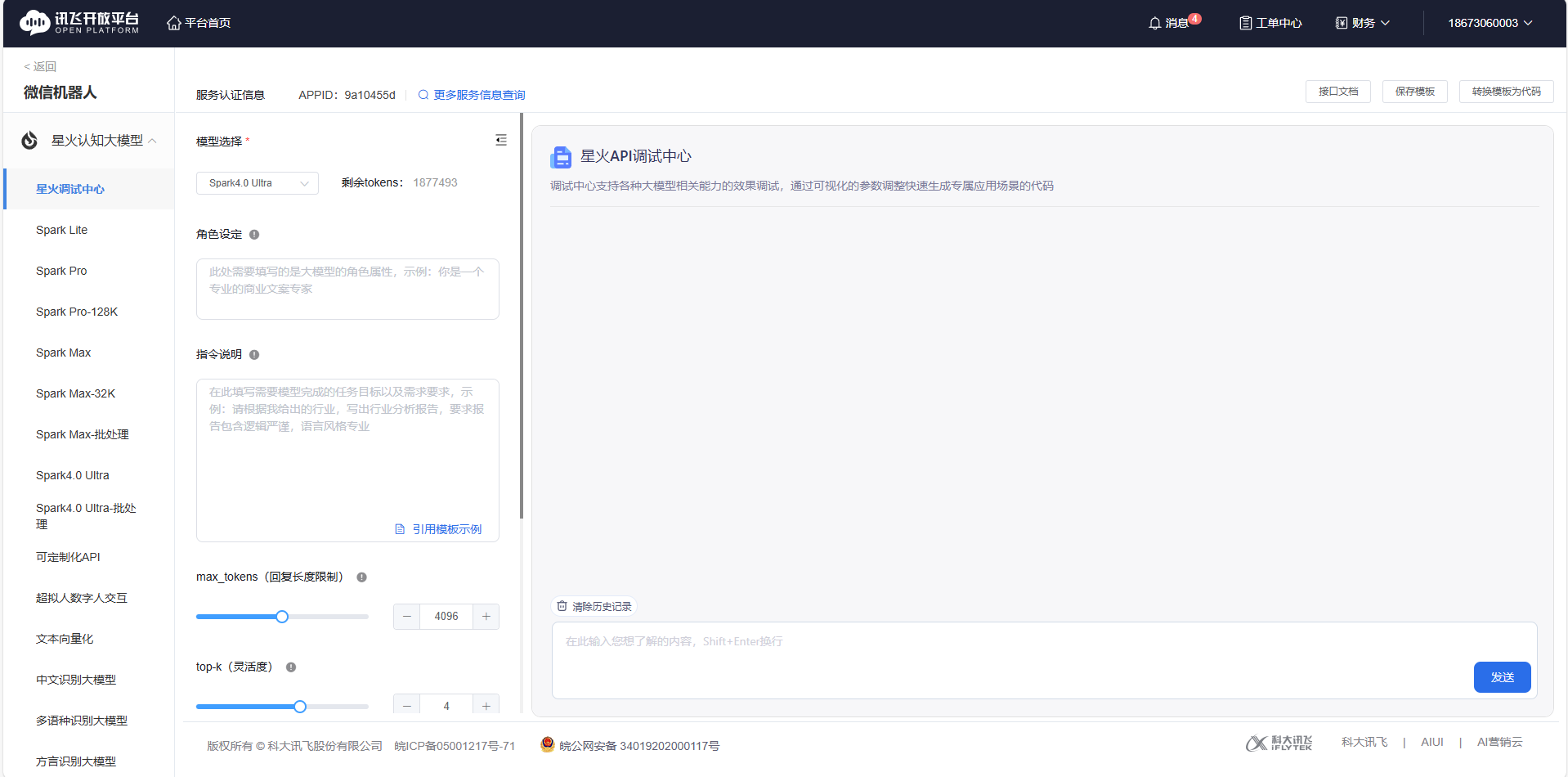 找到你白嫖的模型 并且找到鉴权信息部分 这一部分就相当于调用的账号密码
找到你白嫖的模型 并且找到鉴权信息部分 这一部分就相当于调用的账号密码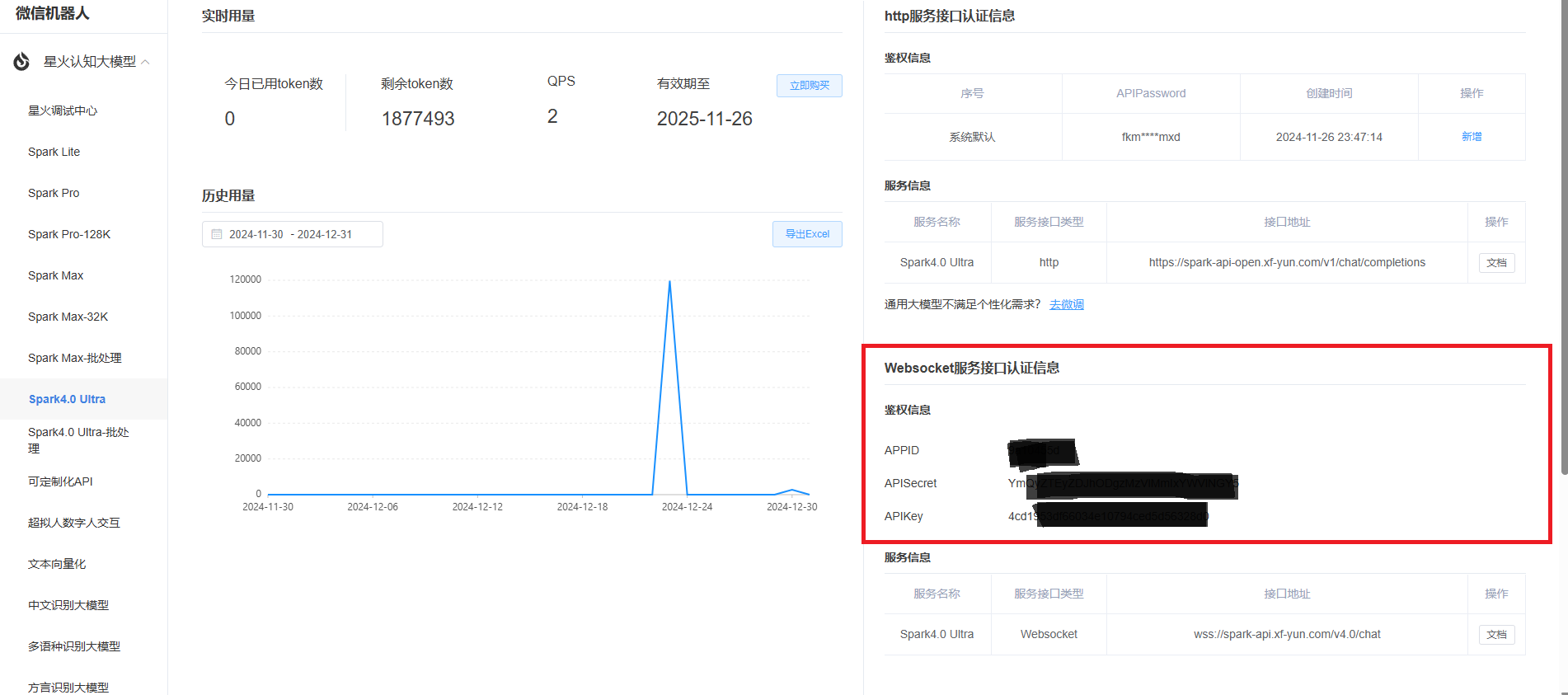
三、代码示例
以下是利用讯飞星火API实现的简单代码示例。
from sparkai.llm.llm import ChatSparkLLM, ChunkPrintHandler
from sparkai.core.messages import ChatMessage
#星火认知大模型Spark 4.0Ultra的URL值,其他版本大模型URL值请前往文档(https://www.xfyun.cn/doc/spark/Web.html)查看
SPARKAI_URL = 'wss://spark-api.xf-yun.com/v4.0/chat'
#星火认知大模型调用秘钥信息,请前往讯飞开放平台控制台(https://console.xfyun.cn/services/bm35)查看
SPARKAI_APP_ID = ' '
SPARKAI_API_SECRET = ''
SPARKAI_API_KEY = ' '
#星火认知大模型Spark 4.0Ultra的domain值,其他版本大模型domain值请前往文档(https://www.xfyun.cn/doc/spark/Web.html)查看
SPARKAI_DOMAIN = '4.0Ultra'
if __name__ == "__main__":
# 创建 ChatSparkLLM 实例
spark = ChatSparkLLM(
spark_api_url=SPARKAI_URL,
spark_app_id=SPARKAI_APP_ID,
spark_api_key=SPARKAI_API_KEY,
spark_api_secret=SPARKAI_API_SECRET,
spark_llm_domain=SPARKAI_DOMAIN,
streaming=False,
temperature=0.9, #随机性 核采样阈值,用于决定结果随机性,取值越高随机性越强,即相同的问题得到的不同答案的可能性越高。取值范围 (0,1],默认为0.5
top_k=4, #核采样数,用于决定结果多样性,取值越大,结果多样性越强,即相同的问题得到的不同答案的可能性越高。取值范围 [1, 10],默认为4
model_kwargs={
'max_tokens': 4096 # 生成文本的最大长度,单位为tokens,1tokens 约等于1.5个中文汉字或者 0.8个英文单词
}
)
messages = [ChatMessage(role="user", content="你好")] #role是用户 user 是用户输入的内容
try:
response = spark.generate([messages])
print("讯飞回复:", response.generations[0][0].text.strip())
except Exception as e:
print("发生错误:", str(e))
运行结果
示例代码运行后,会输出以下回复:
 如果是报错的话一定是没有安装讯飞星火的库 可以用下面的命令安装
如果是报错的话一定是没有安装讯飞星火的库 可以用下面的命令安装
pip install sparkai==0.3.0
pip install spark-ai-python==0.3.9以下是利用讯飞星火API实现的实用代码示例。
# 导入所需的库
import pandas as pd # 用于处理Excel文件
import random # 用于生成随机数
from datetime import datetime, timedelta # 用于处理日期
from sparkai.llm.llm import ChatSparkLLM, ChunkPrintHandler # 导入讯飞星火大模型相关组件
from sparkai.core.messages import ChatMessage # 用于构建对话消息
from openpyxl.styles import Alignment, Font # 用于Excel样式设置
from openpyxl import load_workbook # 用于读写Excel文件
from tqdm import tqdm # 用于显示进度条
# 星火认知大模型的配置参数
SPARKAI_URL = 'wss://spark-api.xf-yun.com/v4.0/chat' # API接口地址
SPARKAI_APP_ID = '' # 应用ID
SPARKAI_API_SECRET = '' # API密钥
SPARKAI_API_KEY = '' # API密钥
SPARKAI_DOMAIN = '4.0Ultra' # 使用的模型版本
# 初始化星火大模型实例
spark = ChatSparkLLM(
spark_api_url=SPARKAI_URL, # API地址
spark_app_id=SPARKAI_APP_ID, # 应用ID
spark_api_key=SPARKAI_API_KEY, # API密钥
spark_api_secret=SPARKAI_API_SECRET, # API密钥
spark_llm_domain=SPARKAI_DOMAIN, # 模型版本
streaming=False, # 是否使用流式输出
temperature=0.9, # 温度参数,控制输出的随机性
top_k=4, # 从前k个候选中随机选择
model_kwargs={'max_tokens': 4096} # 最大输出token数
)
def generate_random_date(start_date, end_date):
"""生成一个随机工作日期(避开周末)"""
# 在起止日期间随机生成一个日期
random_date = start_date + timedelta(days=random.randint(0, (end_date - start_date).days))
# 如果是周末(周六或周日),则重新生成
while random_date.weekday() >= 5: # 5和6分别代表周六和周日
random_date = start_date + timedelta(days=random.randint(0, (end_date - start_date).days))
return random_date
def generate_conversation_details(name):
"""生成谈话的详细内容"""
# 构建提示词
prompt = (
f"你是公司主管,需要与员工{name}进行一次谈话。\n"
f"请按照以下要求生成内容:\n"
f"1. 首先生成一个合理的谈话原因(可以是工作表现、项目进展、职业发展、工作态度等方面)\n"
f"2. 根据谈话原因,生成一段详细的谈话记录,包括主管和{name}的对话内容\n"
f"3. 选择一个合适的谈话地点\n"
f"要求整体内容真实自然,符合企业实际情况。\n"
f"请严格按照以下格式返回:\n"
f"谈话原因:xxx\n"
f"谈话记录:xxx\n"
f"谈话地点:xxx"
)
# 创建对话消息
messages = [ChatMessage(role="user", content=prompt)]
try:
# 调用AI生成回复
response = spark.generate([messages])
result = response.generations[0][0].text.strip()
# 解析AI返回的结果
reason = result.split("谈话原因:")[1].split("\n谈话记录:")[0].strip()
record = result.split("谈话记录:")[1].split("\n谈话地点:")[0].strip()
location = result.split("谈话地点:")[1].strip()
return reason, record, location
except Exception as e:
# 如果发生错误,返回默认值
print(f"生成{name}的谈话内容时发生错误:", str(e))
return "工作表现反馈", "默认谈话记录", "会议室"
def beautify_excel(file_path):
"""美化Excel表格的格式"""
# 加载Excel文件
wb = load_workbook(file_path)
ws = wb.active
# 设置表头样式
header_font = Font(name='宋体', size=14, bold=True)
for cell in ws[1]: # 处理第一行(表头)
cell.font = header_font
cell.alignment = Alignment(horizontal='center', vertical='center', wrap_text=True)
# 设置内容样式
content_font = Font(name='宋体', size=12)
for row in ws.iter_rows(min_row=2): # 处理数据行
for cell in row:
cell.font = content_font
cell.alignment = Alignment(horizontal='center', vertical='center', wrap_text=True)
# 自动调整列宽
for column in ws.columns:
max_length = 0
column_letter = column[0].column_letter
# 计算列中最长的内容
for cell in column:
try:
if len(str(cell.value)) > max_length:
max_length = len(str(cell.value))
except:
pass
# 设置列宽(考虑中文字符宽度)
adjusted_width = max_length * 2
# 设置列宽的最大和最小限制
if adjusted_width > 100:
adjusted_width = 100
elif adjusted_width < 15:
adjusted_width = 15
ws.column_dimensions[column_letter].width = adjusted_width
# 设置表头行高
ws.row_dimensions[1].height = 30
# 自动调整内容行高
for row_idx in range(2, ws.max_row + 1):
max_height = 0
for cell in ws[row_idx]:
if cell.value:
# 计算文本的行数
text_lines = str(cell.value).count('\n') + 1
# 估算所需的行高
required_height = text_lines * 20
max_height = max(max_height, required_height)
# 设置行高的最大和最小限制
if max_height < 30:
max_height = 30
elif max_height > 100:
max_height = 100
ws.row_dimensions[row_idx].height = max_height
# 保存修改后的文件
wb.save(file_path)
def main():
# 读取名单Excel文件,并指定每列的数据类型为字符串
df = pd.read_excel('谈话名单.xlsx', dtype={
'姓名': str,
'谈话时间': str,
'谈话原因': str,
'谈话记录': str,
'谈话地点': str
})
# 设定日期范围
start_date = datetime(2024, 6, 1)
end_date = datetime(2024, 12, 30)
# 遍历每一行生成谈话记录
for index, row in tqdm(df.iterrows(), total=len(df), desc="生成谈话记录"):
name = row['姓名']
# 生成随机谈话日期
random_date = generate_random_date(start_date, end_date)
# 生成谈话内容
reason, record, location = generate_conversation_details(name)
# 更新数据框中的相应字段
df.loc[index, '谈话时间'] = random_date.strftime('%Y-%m-%d')
df.loc[index, '谈话原因'] = reason
df.loc[index, '谈话记录'] = record
df.loc[index, '谈话地点'] = location
# 保存为新的Excel文件
output_file = '谈话记录.xlsx'
df.to_excel(output_file, index=False)
# 美化Excel格式
beautify_excel(output_file)
# 程序入口
if __name__ == "__main__":
main()这是一个基于讯飞星火大模型的企业谈话记录生成工具。会根据谈话名单.xlsx生成一个谈话记录.xlsx,主要功能和特点如下:
自动生成企业主管与员工的谈话记录
生成的内容包括:谈话原因、谈话记录和谈话地点
自动分配合理的谈话时间(避开周末)
自动美化输出的Excel文件格式
 运行结果
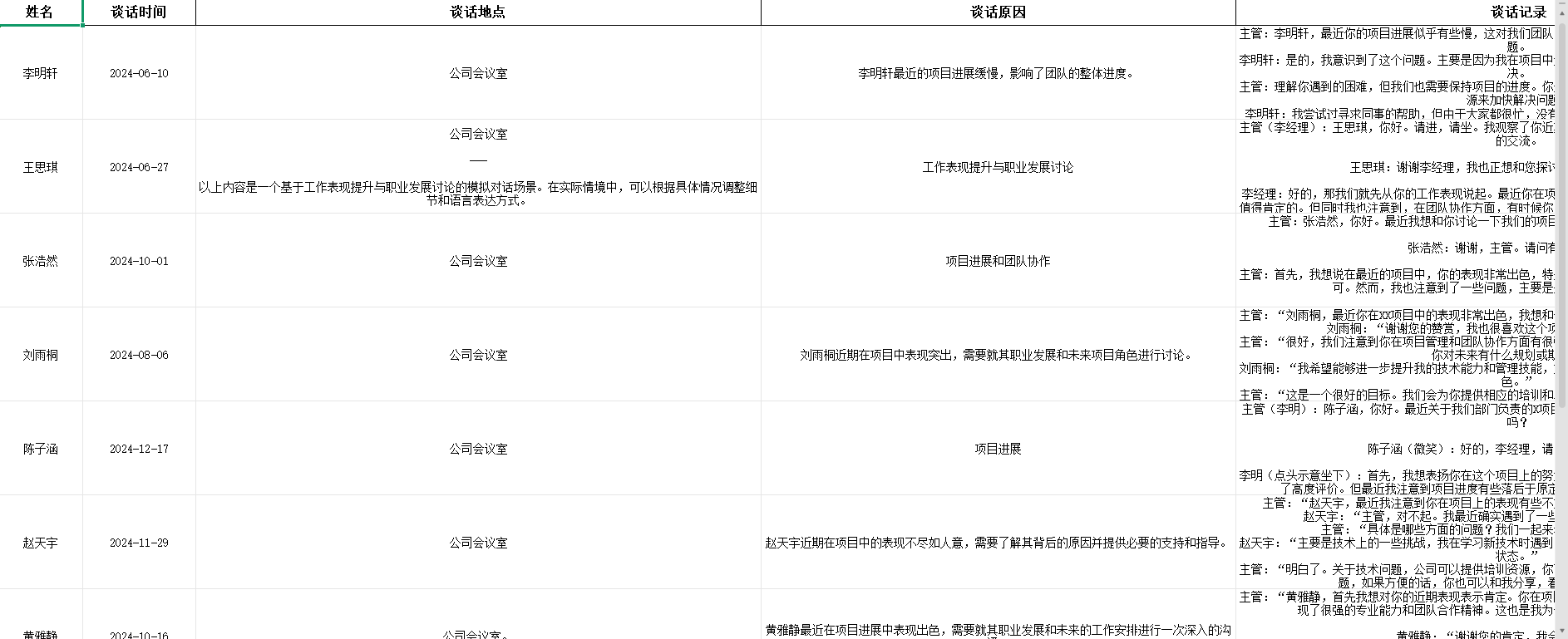
运行结果
示例代码运行后,会输出以下回复:

五、总结
讯飞星火API的接入和使用相对简单,能够有效提升工作效率,尤其是在需要处理大量文本或生成内容的场景中。
通过Python代码的集成,可以进一步扩展API的应用范围,实现自动化的工作流程。